训练多智能体强化学习算法¶
MPE 是一个常用的多智能体训练环境,用于测试各种多智能体强化学习算法的性能。 由于MPE有安装简单,方便定制化,易于可视化等优点,使其成为入门多智能体强化学习的理想环境。 我们将在本教程中介绍如何使用多智能体PPO训练MPE智能体。 下图展示了MPE中的一个简单的环境(simple_spread),智能体需要控制3个蓝色小球到达3个黑点标记的目标点。 左边是通过OpenRL框架训练出来的智能体,右边是随机动作的智能体。
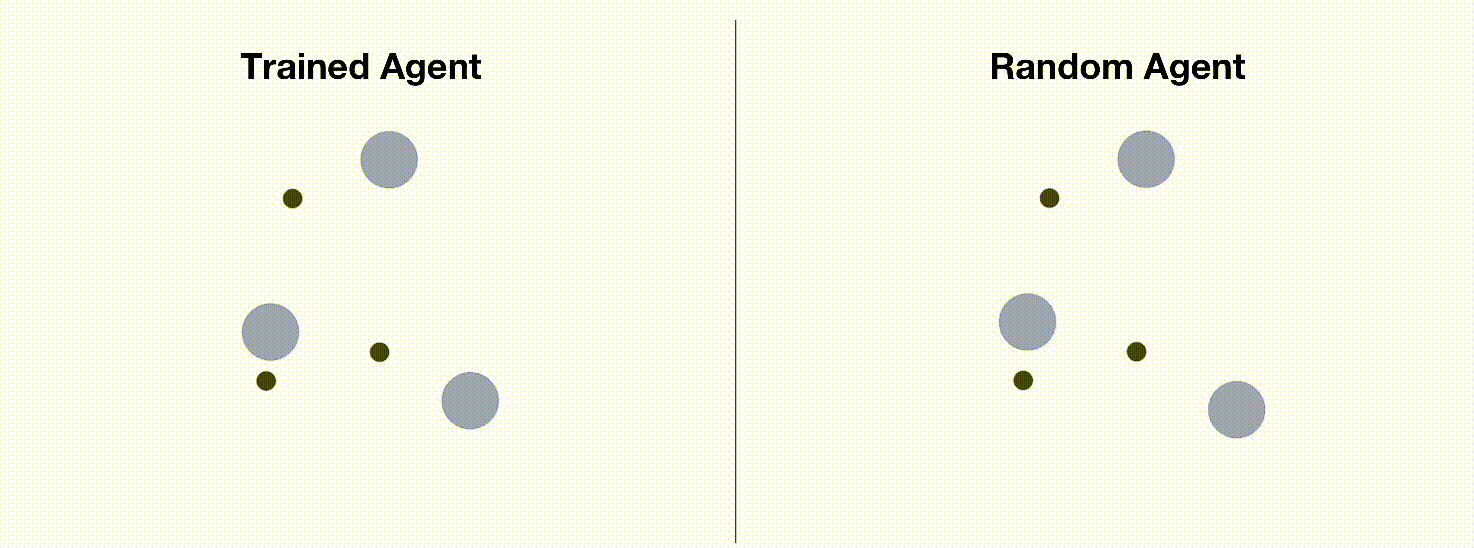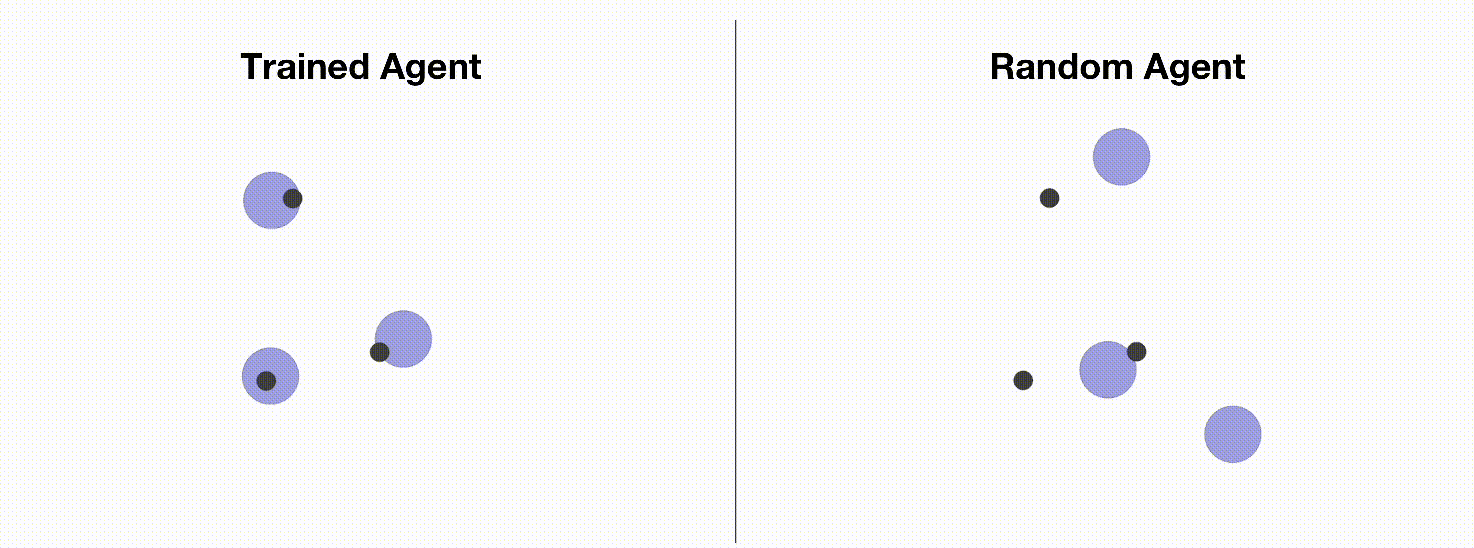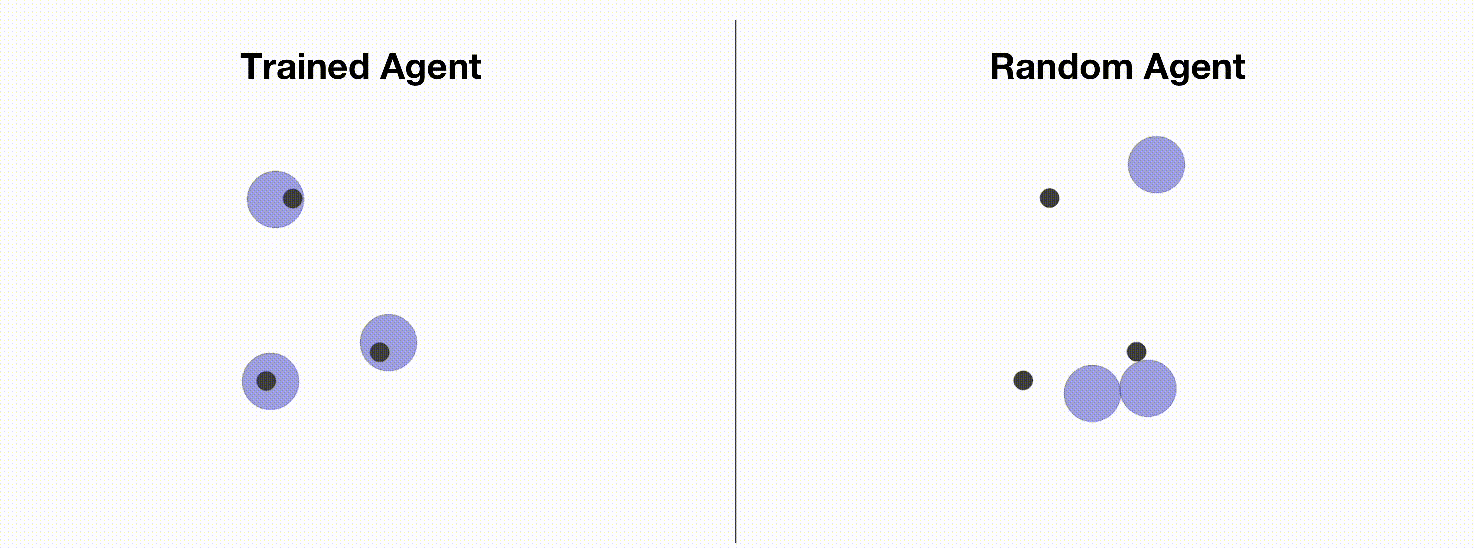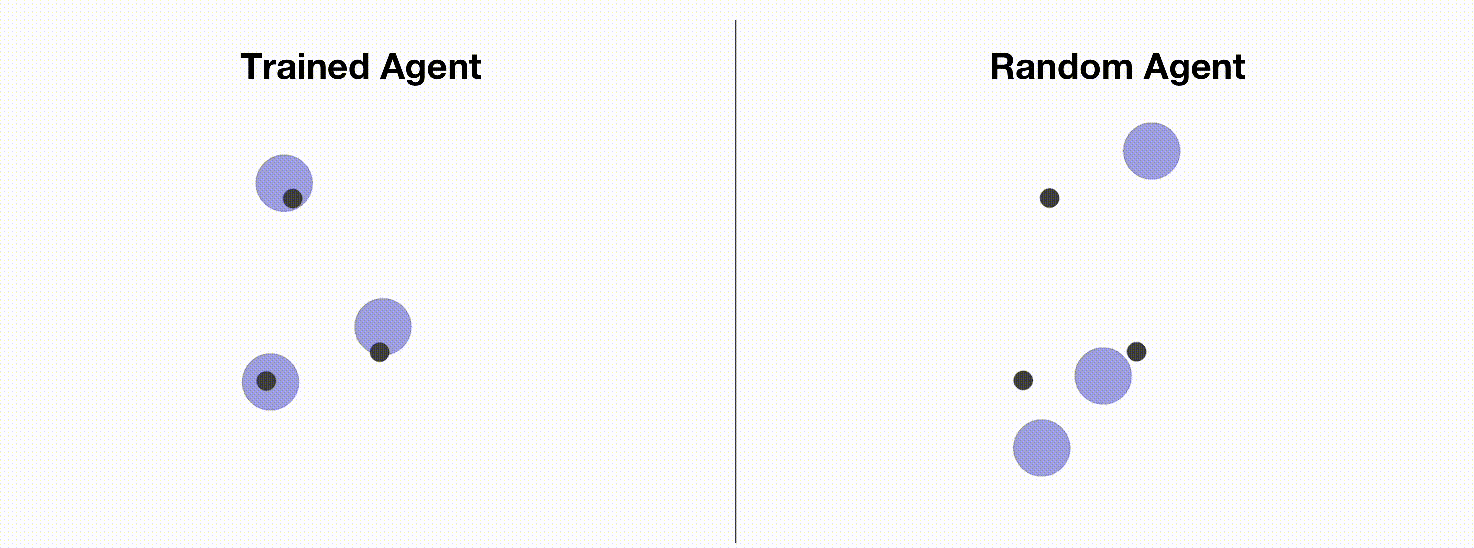
和训练 CartPole 环境一样,我们可以创建一个 train_ppo.py 文件,然后在其中编写训练代码:
# train_ppo.py
from openrl.envs.common import make
from openrl.modules.common import PPONet as Net
from openrl.runners.common import PPOAgent as Agent
def train():
# 创建 MPE 环境,使用异步环境,即每个智能体独立运行
env = make(
"simple_spread",
env_num=100,
asynchronous=True,
)
# 创建 神经网络,使用GPU进行训练
net = Net(env, device="cuda")
agent = Agent(net) # 初始化训练器
# 开始训练
agent.train(total_time_steps=5000000)
# 保存训练完成的智能体
agent.save("./ppo_agent/")
if __name__ == "__main__":
train()
相比于 CartPole 环境,我们在创建MPE环境时,
使用了 asynchronous=True,这样每个环境能够独立运行,从而提升环境的数据采样效率。
默认情况下, asynchronous=False,这时每个环境将会按照顺序依次执行。
此外,为了保存训练完成后的智能体,我们使用了 agent.save() 函数,将智能体保存在 "./ppo_agent/" 文件夹中。
小技巧
用户可以在 openrl/example 里找到该部分的示例代码。
通过配置文件修改训练参数¶
这个训练脚本依然使用的是默认参数,我们还可以方便地通过编写配置文件来修改训练超参数。
首先,我们修改 train_ppo.py 文件,在其中添加读取配置文件的代码,并把读取的配置传给神经网络 Net() :
# train_ppo.py
from openrl.envs.common import make
from openrl.modules.common import PPONet as Net
from openrl.runners.common import PPOAgent as Agent
from openrl.configs.config import create_config_parser
def train():
# 添加读取配置文件的代码
cfg_parser = create_config_parser()
cfg = cfg_parser.parse_args()
# 创建 MPE 环境,使用异步环境,即每个智能体独立运行
env = make(
"simple_spread",
env_num=100,
asynchronous=True,
)
# 创建 神经网络,传入超参数的配置
net = Net(env, cfg=cfg, device="cuda")
agent = Agent(net) # 初始化训练器
# 开始训练
agent.train(total_time_steps=5000000)
# 保存训练完成的智能体
agent.save("./ppo_agent/")
if __name__ == "__main__":
train()
然后,我们在与 train_ppo.py 的同一目录下创建一个 mpe_ppo.yaml 文件,用于存放训练超参数的配置:
# mpe_ppo.yaml
seed: 0 # 设置seed,保证每次实验结果一致
lr: 7e-4 # 设置policy模型的学习率
critic_lr: 7e-4 # 设置critic模型的学习率
episode_length: 25 # 设置每个episode的长度
use_recurrent_policy: true # 设置是否使用RNN
use_joint_action_loss: true # 设置是否使用JRPO算法
use_valuenorm: true # 设置是否使用value normalization
use_adv_normalize: true # 设置是否使用advantage normalization
在这个配置文件中,我们设置了本次训练的seed,学习率,episode长度,是否使用RNN,是否使用 JRPO算法 等超参数。
最后,我们在终端中执行 python train_ppo.py --config mpe_ppo.yaml ,即可开始训练。
小技巧
除了通过读入配置文件的方式修改超参数,我们还可以通过命令行的方式修改超参数。 比如用户可以直接通过执行:
python train_ppo.py --seed 1 --lr 5e-4
来修改seed和学习率。当超参数过多时,我们推荐使用配置文件的方式来传递超参数。
注解
训练该MPE任务大约耗时30分钟,训练完成后,可在与 train_ppo.py 的同一目录下找到 ppo_agent 文件夹,其中包含了训练完成的智能体。
接下来,我们将继续介绍如何在OpenRL框架中使用wandb来可视化训练过程,用户可在完成wandb使用教程后再开始实际的训练。
使用wandb跟踪训练过程¶
对于还不熟悉wandb的用户,可以先通过 wandb知乎教程 进行学习。 用户需要预先完成wandb的账号注册,安装以及基础概念的学习。
使用wandb,需要指定wandb团队名称,实验名称,实验数据保存的路径等信息。当然,这些我们都可以方便地通过配置文件来指定。 只需要在配置文件中加入以下内容:
# mpe_ppo.yaml
wandb_entity: openrl # 这里用于指定wandb团队名称,请把openrl替换为你自己的团队名称
experiment_name: ppo # 这里用于指定实验名称
run_dir: ./exp_results/ # 这里用于指定实验数据保存的路径
log_interval: 10 # 这里用于指定每隔多少个episode上传一次wandb数据
seed: 0 # 设置seed,保证每次实验结果一致
lr: 7e-4 # 设置policy模型的学习率
critic_lr: 7e-4 # 设置critic模型的学习率
episode_length: 25 # 设置每个episode的长度
use_recurrent_policy: true # 设置是否使用RNN
use_joint_action_loss: true # 设置是否使用JRPO算法
use_valuenorm: true # 设置是否使用value normalization
use_adv_normalize: true # 设置是否使用advantage normalization
写好配置文件后,我们只需要在 train_ppo.py 文件中设置 Agent(net, use_wandb=True) 即可:
# train_ppo.py
from openrl.envs.common import make
from openrl.modules.common import PPONet as Net
from openrl.runners.common import PPOAgent as Agent
from openrl.configs.config import create_config_parser
def train():
# 添加读取配置文件的代码
cfg_parser = create_config_parser()
cfg = cfg_parser.parse_args()
# 创建 MPE 环境,使用异步环境,即每个智能体独立运行
env = make(
"simple_spread",
env_num=100,
asynchronous=True,
)
# 创建 神经网络,传入超参数的配置
net = Net(env, cfg=cfg, device="cuda")
# 使用wandb
agent = Agent(net, use_wandb=True)
# 开始训练
agent.train(total_time_steps=5000000)
# 保存训练完成的智能体
agent.save("./ppo_agent/")
if __name__ == "__main__":
train()
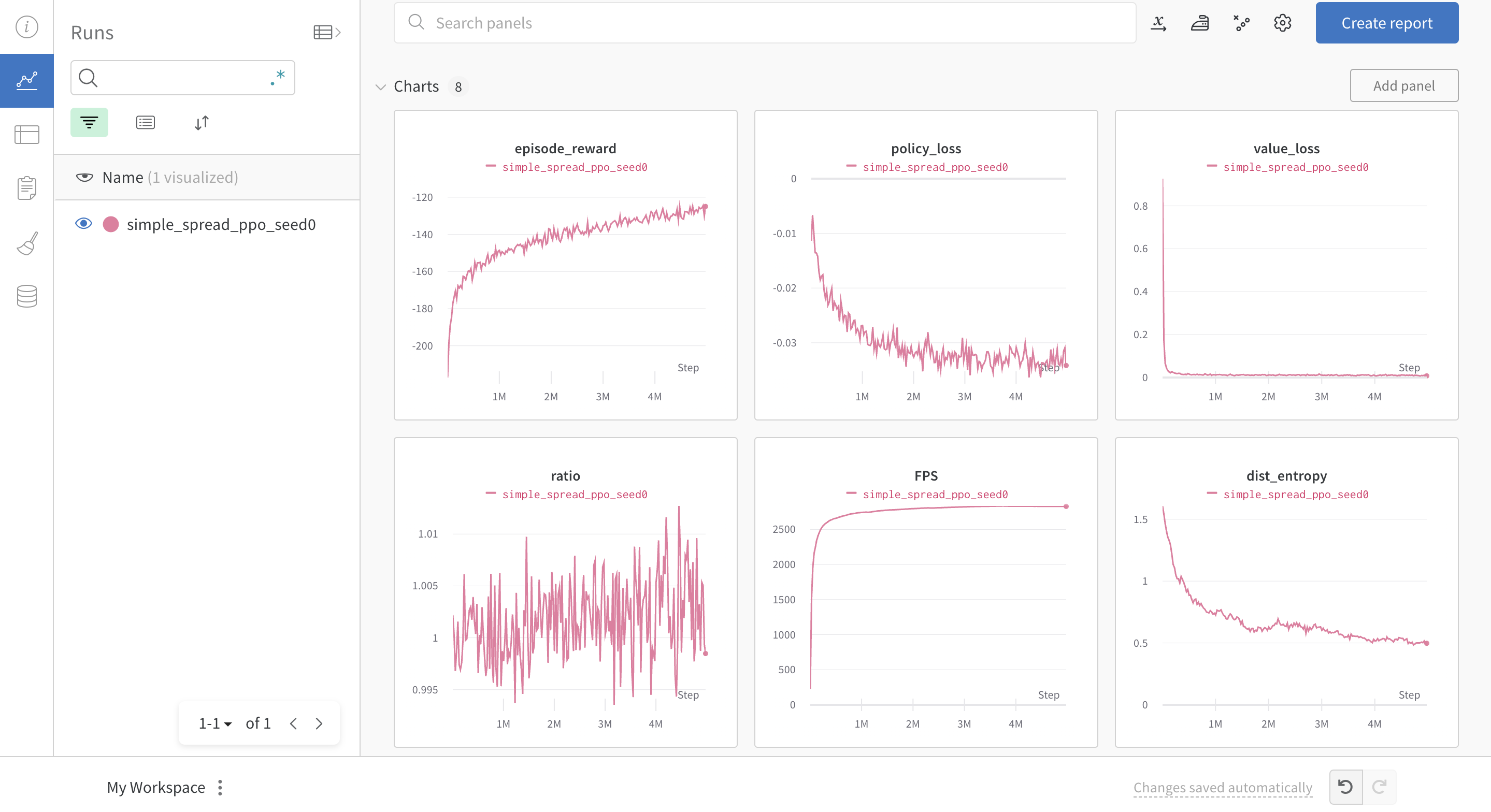
执行 python train_ppo.py --config mpe_ppo.yaml ,即可开始训练。过一会儿,用户便可以在wandb网站上看到如下的训练过程:
加载训练好的智能体¶
智能体训练完成并保存后,我们可以通过 agent.load() 来加载训练好的智能体,并进行测试。让我们新建一个名为 eval_ppo.py 的文件,用于测试训练好的智能体:
# eval_ppo.py
from openrl.envs.common import make
from openrl.modules.common import PPONet as Net
from openrl.runners.common import PPOAgent as Agent
from openrl.envs.wrappers import GIFWrapper # 用于生成gif
def evaluation():
# 创建 MPE 环境
env = make( "simple_spread", env_num=4)
# 使用GIFWrapper,用于生成gif
env = GIFWrapper(env, "test_simple_spread.gif")
agent = Agent(Net(env)) # 创建 智能体
# 加载训练好的模型
agent.load('./ppo_agent/')
# 开始测试
obs, _ = env.reset()
while True:
# 智能体根据 observation 预测下一个动作
action, _ = agent.act(obs)
obs, r, done, info = env.step(action)
if done.any():
break
env.close()
if __name__ == "__main__":
evaluation()
然后,我们在终端中执行 python eval_ppo.py ,即可开始测试。测试完成后,
我们可以在当前目录下找到 test_simple_spread.gif 文件,用于观察智能体的表现:
