训练自然语言对话任务¶
这部分我们将通过一个自然语言对话任务( DailyDialog )来介绍如何在OpenRL中导入 Hugging Face 模型和数据、 如何使用 自定义奖励模型 以及如何 自定义 wandb 的输出 等。
DailyDialog任务介绍¶
DailyDialog 是一个英文的多轮对话数据集,一共包含1.3万条对话数据。 下图展示了DailyDialog中的一段对话示例:

过去,这类自然语言任务通常都是使用监督学习来进行训练, 但最近的研究表明,强化学习也可以用于训练语言模型, 并且能显著提升模型的性能(参考[1][2][3])。
接下来,我们将详细介绍如何使用OpenRL来完成自然语言任务的训练。
创建环境与加载数据¶
自然语言任务训练涉及到一些额外包的使用,用户可以通过以下命令完成相关包的安装:
pip install "openrl[nlp]"
和前面介绍过的使用教程(MPE )一样,
我们首先需要编写一个 train_ppo.py 文件,编写以下训练代码:
# train_ppo.py
from openrl.envs.common import make
from openrl.modules.common import PPONet as Net
from openrl.runners.common import PPOAgent as Agent
from openrl.configs.config import create_config_parser
def train():
# 添加读取配置文件的代码
cfg_parser = create_config_parser()
cfg = cfg_parser.parse_args()
# 创建 NLP 环境
env = make("daily_dialog",env_num=2,asynchronous=True,cfg=cfg)
# 创建 神经网络
net = Net(env, cfg=cfg, device="cuda")
# 创建训练智能体
agent = Agent(net)
# 开始训练
agent.train(total_time_steps=100000)
# 保存训练完成的智能体
agent.save("./ppo_agent/")
if __name__ == "__main__":
train()
然后,我们可以创建一个配置文件 nlp_ppo.yaml ,并加入以下内容:
# nlp_ppo.yaml
env: # 环境所用到的参数
args: {
"tokenizer_path": gpt2, # 读取tokenizer的路径
"data_path": daily_dialog # 数据集路径
}
seed: 0 # 设置seed,保证每次实验结果一致
lr: 1e-6 # 设置policy模型的学习率
critic_lr: 1e-6 # 设置critic模型的学习率
episode_length: 20 # 设置每个episode的长度
use_recurrent_policy: true
从上面配置文件可以看出,训练NLP任务需要额外设置 环境参数 env.args。
其中,环境参数中的 data_path 可以设置为 Hugging Face数据集名称 或者 本地数据集路径。
而 tokenizer_path 则用于指定加载文字编码器的 Hugging Face名称 或者 本地路径。
使用 Hugging Face 的模型进行训练¶
在OpenRL中,我们可以使用 Hugging Face 上的模型来进行训练。
为了加载Hugging Face上的模型,我们首先需要在配置文件 nlp_ppo.yaml 中添加以下内容:
# nlp_ppo.yaml
model_path: rajkumarrrk/gpt2-fine-tuned-on-daily-dialog # 预训练模型路径
use_share_model: true # 策略网络和价值网络是否共享模型
ppo_epoch: 5 # ppo训练迭代次数
env: # 环境所用到的参数
args: {
"tokenizer_path": gpt2, # 读取tokenizer的路径
"data_path": daily_dialog # 数据集路径
}
lr: 1e-6 # 设置policy模型的学习率
critic_lr: 1e-6 # 设置critic模型的学习率
episode_length: 128 # 设置每个episode的长度
num_mini_batch: 20
然后需要在 train_ppo.py 中添加以下代码:
# train_ppo.py
from openrl.envs.common import make
from openrl.modules.common import PPONet as Net
from openrl.runners.common import PPOAgent as Agent
from openrl.configs.config import create_config_parser
from openrl.modules.networks.policy_value_network_gpt import (
PolicyValueNetworkGPT as PolicyValueNetwork,
)
def train():
# 添加读取配置文件的代码
cfg_parser = create_config_parser()
cfg = cfg_parser.parse_args()
# 创建 NLP 环境
env = make("daily_dialog",env_num=2,asynchronous=True,cfg=cfg)
# 创建 神经网络
model_dict = {"model": PolicyValueNetwork}
net = Net(env, cfg=cfg, model_dict=model_dict)
# 创建训练智能体
agent = Agent(net)
# 开始训练
agent.train(total_time_steps=100000)
# 保存训练完成的智能体
agent.save("./ppo_agent/")
if __name__ == "__main__":
train()
通过以上简单几行的修改,用户便可以使用Hugging Face上的预训练模型进行训练。
注解
上面这个例子中,我们使用了
PolicyValueNetworkGPT这个模型。 OpenRL还支持用户自定义模型(例如自定模型为CustomPolicyValueNetwork),然后通过model_dict = {"model": CustomPolicyValueNetwork} net = Net(env, model_dict=model_dict)
的方式传入训练网络。如果想要分别实现策略网络和价值网络,可以通过
model_dict = { "policy": CustomPolicyNetwork, "critic": CustomValueNetwork, } net = Net(env, model_dict=model_dict)
来实现。自定义模型的实现方式可以参考 PolicyValueNetworkGPT、PolicyNetwork 以及 ValueNetwork。
使用奖励模型¶
通常,自然语言任务的数据集中并不包含奖励信息。 因此,如果需要使用强化学习来训练自然语言任务,就需要使用额外的奖励模型来生成奖励。
在该DailyDialog任务中,我们将会使用一个复合的奖励模型,它包含以下三个部分:
意图奖励:即当智能体生成的语句和期望的意图接近时,智能体便可以获得更高的奖励。
METEOR指标奖励: METEOR 是一个用于评估文本生成质量的指标,它可以用来衡量生成的语句和期望的语句的相似程度。我们把这个指标作为奖励反馈给智能体,以达到优化生成的语句的效果。
KL散度奖励:该奖励用来限制智能体生成的文本偏离预训练模型的程度,防止出现reward hacking的问题。
我们最终的奖励为以上三个奖励的加权和,其中 KL散度奖励 的系数是随着KL散度的大小动态变化的。
想在OpenRL中使用该奖励模型,用户无需修改训练代码,只需要在 nlp_ppo.yaml 文件中添加 reward_class 参数即可:
# nlp_ppo.yaml
reward_class:
id: NLPReward # 奖励模型名称
args: {
# 用于意图判断的模型的名称或路径
"intent_model": rajkumarrrk/roberta-daily-dialog-intent-classifier,
# 用于计算KL散度的预训练模型的名称或路径
"ref_model": rajkumarrrk/gpt2-fine-tuned-on-daily-dialog,
}
model_path: rajkumarrrk/gpt2-fine-tuned-on-daily-dialog # 预训练模型路径
use_share_model: true
ppo_epoch: 5 # ppo训练迭代次数
env: # 环境所用到的参数
args: {
"tokenizer_path": gpt2, # 读取tokenizer的路径
"data_path": daily_dialog # 数据集路径
}
lr: 1e-6 # 设置policy模型的学习率
critic_lr: 1e-6 # 设置critic模型的学习率
episode_length: 128 # 设置每个episode的长度
num_mini_batch: 20
注解
OpenRL支持用户使用自定义的奖励模型。
首先,用户需要编写自定义奖励模型(需要继承 BaseReward 类)。
接着,用户需要注册自定义的奖励模型,即在 train_ppo.py 添加以下代码:
# train_ppo.py
from openrl.rewards.nlp_reward import CustomReward
from openrl.rewards import RewardFactory
RewardFactory.register("CustomReward", CustomReward)
最后,用户需要在 nlp_ppo.yaml 中填写自定义的奖励模型即可:
reward_class:
id: "CustomReward" # 自定义奖励模型名称
args: {} # 用户自定义奖励模型可能用到的参数
自定义wandb输出¶
OpenRL还支持用户自定义wandb和tensorboard的输出内容。
例如,在该任务的训练过程中,我们还需要输出各种类型奖励的信息和KL散度系数的信息,
用户可以在 nlp_ppo.yaml 文件中加入 vec_info_class 参数来实现:
# nlp_ppo.yaml
vec_info_class:
id: "NLPVecInfo" # 调用NLPVecInfo类以打印NLP任务中的奖励信息
#设置wandb信息
wandb_entity: openrl # 这里用于指定wandb团队名称,请把openrl替换为你自己的团队名称
experiment_name: train_nlp # 这里用于指定实验名称
run_dir: ./run_results/ # 这里用于指定实验数据保存的路径
log_interval: 1 # 这里用于指定每隔多少个episode上传一次wandb数据
# 自行填写其他参数...
修改完配置文件后,在 train_ppo.py 文件中启用wandb:
# train_ppo.py
agent.train(total_time_steps=100000, use_wandb=True)
然后执行 python train_ppo.py --config nlp_ppo.yaml ,过一会儿,便可以在wandb中看到如下的输出:
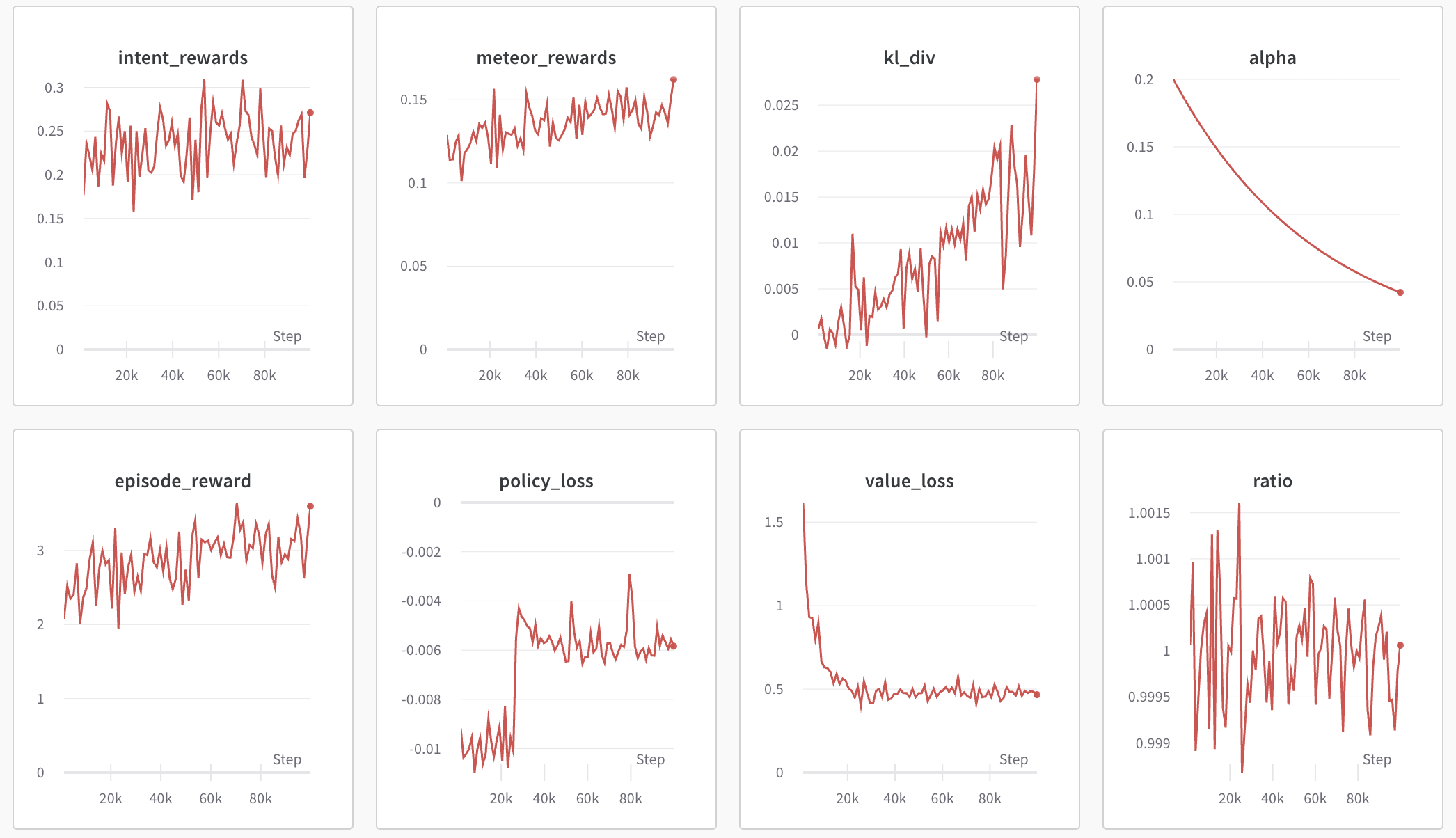
从上图可以看到,wandb输出了各种类型奖励的信息和KL散度系数的信息。
如果用户还需要输出其他信息,还可以参考 NLPVecInfo 类
和 VecInfo 类来实现自己的 CustomVecInfo 类。
然后,需要在 train_ppo.py 中注册自定义的 CustomVecInfo 类:
# train_ppo.py
# 注册自定义输出信息类
VecInfoFactory.register("CustomVecInfo", CustomVecInfo)
最后,只需要在 nlp_ppo.yaml 中填写 CustomVecInfo 类即可:
# nlp_ppo.yaml
vec_info_class:
id: "CustomVecInfo" # 调用自定义CustomVecInfo类以输出自定义信息
使用混合精度训练加速¶
OpenRL还提供了一键开启混合精度训练的功能。用户只需要在配置文件中加入以下参数即可:
# nlp_ppo.yaml
use_amp: true # 开启混合精度训练
小技巧
用户可以在 train_ppo.py 里找到训练nlp任务的示例代码。 并在 nlp_ppo.yaml 里找到训练nlp任务的各项参数。 用户可以执行 python train_ppo.py --config nlp_ppo.yaml 指令以训练对话任务。
使用 DeepSpeed 加速训练¶
OpenRL 还提供了一项功能,可以一步启用 DeepSpeed 训练。用户首先需要添加两个配置文件:
# ds_config.yaml
{
"train_batch_size": 32, # train_batch_size = episode_length * env_num / num_mini_batch
"train_micro_batch_size_per_gpu": 16, # train_micro_batch_size_per_gpu = train_batch_size / num_gpu
"steps_per_print": 10,
"zero_optimization": {
"stage": 2, # 默认使用 Zero2
"reduce_bucket_size": 5e7,
"allgather_bucket_size": 5e7
},
"fp16": {"enabled": false, "loss_scale_window": 100} # 是否使用fp16
}
# eval_ds_config.yaml
{
"train_batch_size": 32,
"train_micro_batch_size_per_gpu": 16,
"steps_per_print": 10,
"zero_optimization": {
"stage": 0, # 默认对 ref_model 和奖励模型使用 cpu_offload
"offload_param": {"device": "cpu"}
},
"fp16": {"enabled": false} # 是否使用fp16
}
接下来在 nlp_ppo_ds.yaml 中启用 DeepSpeed:
use_deepspeed: true
use_fp16: false
use_offload: false
deepspeed_config: ds_config.json
reward_class:
id: "NLPReward"
args: {
"use_deepspeed": true,
"ref_ds_config": "eval_ds_config.json",
"ref_model": "rajkumarrrk/gpt2-fine-tuned-on-daily-dialog",
"intent_ds_config": "eval_ds_config.json",
"intent_model": "rajkumarrrk/roberta-daily-dialog-intent-classifier",
}
小技巧
episode_length 和 num_mini_batch 可以在 nlp_ppo_ds.yaml 中找到;
env_num 可以在 train_ppo.py 中找到;
请确保所有参数满足以下关系:train_batch_size = episode_length * env_num / num_mini_batch 。
最后执行以下命令即可启动训练:
deepspeed train_ppo.py --config nlp_ppo_ds.yaml
OpenRL训练结果¶
下表格展示了使用OpenRL训练该对话任务的结果。结果显示使用强化学习训练后,模型各项指标均有所提升。 另外,从下表可以看出,相较于 RL4LMs , OpenRL的训练速度更快(在同样3090显卡的机器上,速度提升 17.2% ),最终的性能指标也更好。
FPS(训练速度) |
Rouge-1 |
Rouge-Lsum |
Meteor |
SacreBLEU |
意图奖励 |
平均预测语句长度 |
|
|---|---|---|---|---|---|---|---|
监督学习 |
None |
0.164 |
0.137 |
0.234 |
0.063 |
0.427 |
18.95 |
RL4LMs |
11.26 |
0.169 |
0.144 |
0.198 |
0.071 |
0.455 |
18.83 |
OpenRL |
13.20(+17%) |
0.181(+10%) |
0.153(+12%) |
0.292(+25%) |
0.090(+43%) |
0.435(+1.9%) |
18.69 |
下表显示,与采用 DataParallel 的 OpenRL 相比,采用 DeepSpeed 的 OpenRL 具有更快的训练速度:
FPS(Speed) |
Number of GPUs |
Memory Usage per GPU(MB) |
GPU Type |
Train Micro Batch Size per GPU |
|
|---|---|---|---|---|---|
DeepSpeed w/ GPT-2-small |
5.11(+30%) |
2 |
13537 |
RTX 3090 |
8 |
Data-Parallel w/ GPT-2-small |
3.94 |
2 |
7207 |
RTX 3090 |
8 |
DeepSpeed w/ OPT-1.3B |
7.09(+35%) |
4 |
35360 |
NVIDIA A100 |
8 |
Data-Parallel w/ OPT-1.3B |
5.25 |
4 |
15854 |
NVIDIA A100 |
8 |
和训练好的智能体进行对话¶
对于训练好的智能体,用户可以方便地通过 agent.chat() 接口进行对话:
# chat.py
from openrl.runners.common import ChatAgent as Agent
def chat():
agent = Agent.load("./ppo_agent", tokenizer="gpt2",)
history = []
print("Welcome to OpenRL!")
while True:
input_text = input("> User: ")
if input_text == "quit":
break
elif input_text == "reset":
history = []
print("Welcome to OpenRL!")
continue
response = agent.chat(input_text, history)
print(f"> OpenRL Agent: {response}")
history.append(input_text)
history.append(response)
if __name__ == "__main__":
chat()
小技巧
用户可以在 chat.py 里找到该部分的示例代码。 此外,我们还在 chat_6b.py 提供了一个和 ChatGLM-6B 模型聊天的示例。
执行 python chat.py ,便可以和训练好的智能体进行对话了:
