Train Your First Agent¶
Training Environment¶
OpenRL provides users with a simple and easy-to-use way of using it. Here we take the CartPole environment as an example, to demonstrate how to use OpenRL for reinforcement learning training. Create a new file train_ppo.py and enter the following code:
# train_ppo.py
from openrl.envs.common import make
from openrl.modules.common import PPONet as Net
from openrl.runners.common import PPOAgent as Agent
env = make("CartPole-v1", env_num=9) # create environment, set environment parallelism to 9
net = Net(env) # create the neural network
agent = Agent(net) # initialize the trainer
# start training, set total number of training steps to 20000
agent.train(total_time_steps=20000)
Execute python train_ppo.py in the terminal to start training. On an ordinary laptop, it takes only a few seconds to complete the agent’s training.
Tip
OpenRL also provides command line tools that allow you to complete agent training with one command. Users only need to execute the following command in the terminal:
openrl --mode train --env CartPole-v1
Test Environment¶
After the agents have completed their training, we can use the agent.act() method to obtain actions.
Just add this code snippet into your train_ppo.py file and visualize test results:
# train_ppo.py
from openrl.envs.common import make
from openrl.modules.common import PPONet as Net
from openrl.runners.common import PPOAgent as Agent
env = make("CartPole-v1", env_num=9) # create environment, set environment parallelism to 9
net = Net(env) # create neural network
agent = Agent(net) # initialize trainer
agent.train(total_time_steps=20000) # start training, set total number of training steps to 20000
# Create an environment for testing and set the number of environments to interact with to 9. Set rendering mode to group_human.
env = make("CartPole-v1", env_num=9, render_mode="group_human")
agent.set_env(env) # The trained agent sets up the interactive environment it needs.
# Initialize the environment and get initial observations and environmental information.
obs, info = env.reset()
while True:
action, _ = agent.act(obs) # Based on environmental observation input, predict next action.
obs, r, done, info = env.step(action)
if any(done): break
env.close()
Execute python train_ppo.py in your terminal window to start training and visualize test results.
The train_ppo.py code can also be downloaded from openrl/examples .
Demonstration:
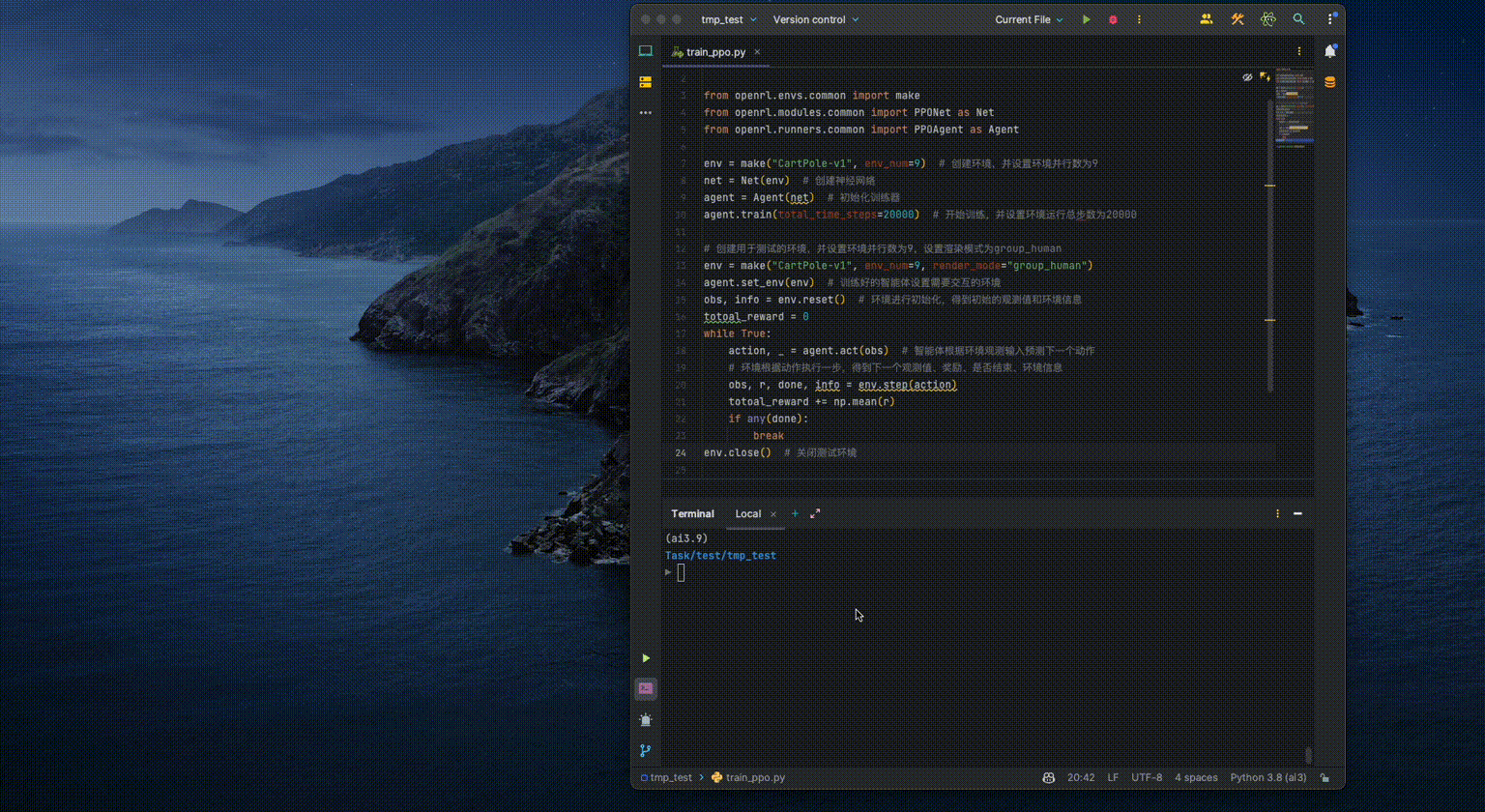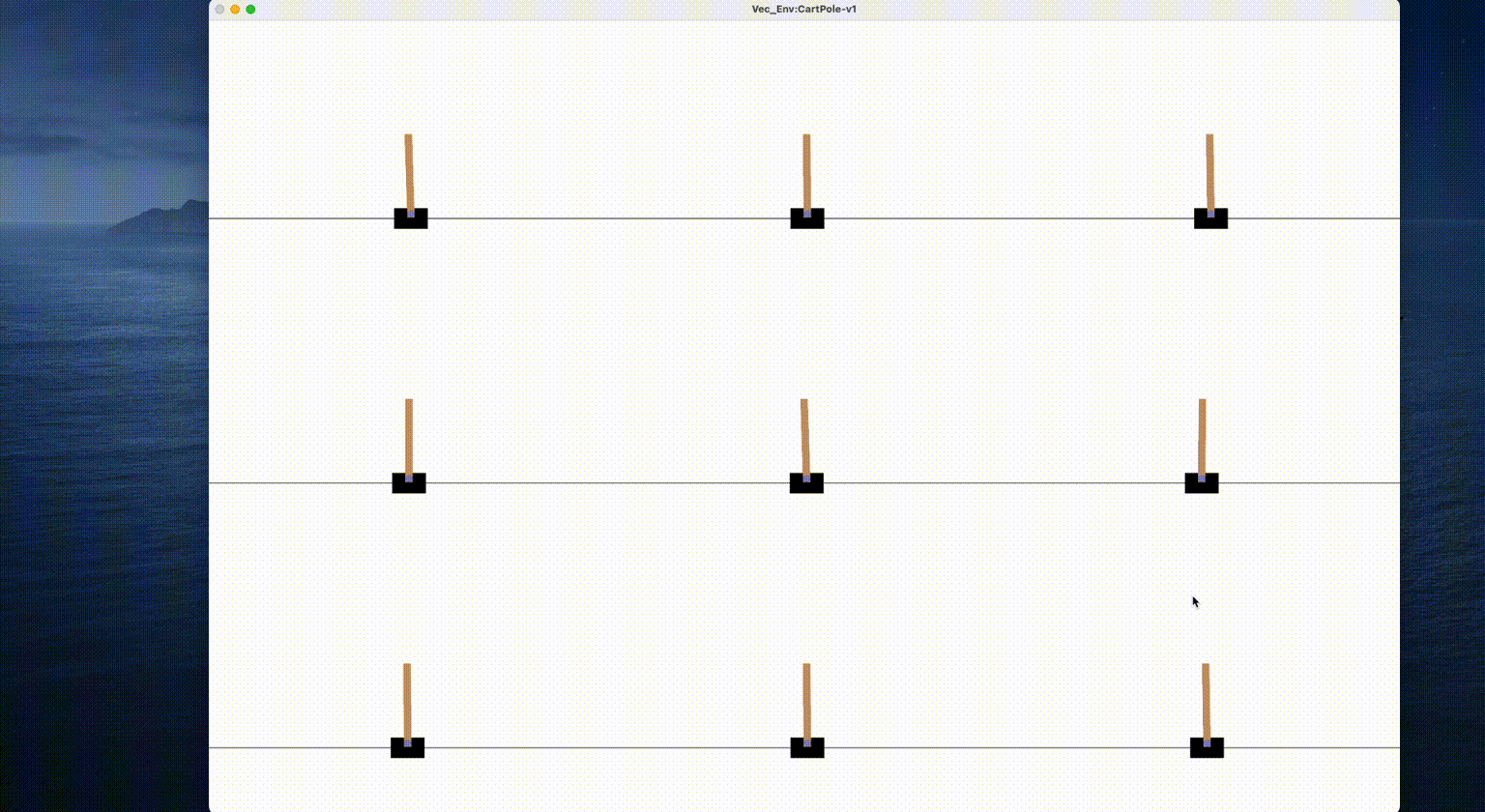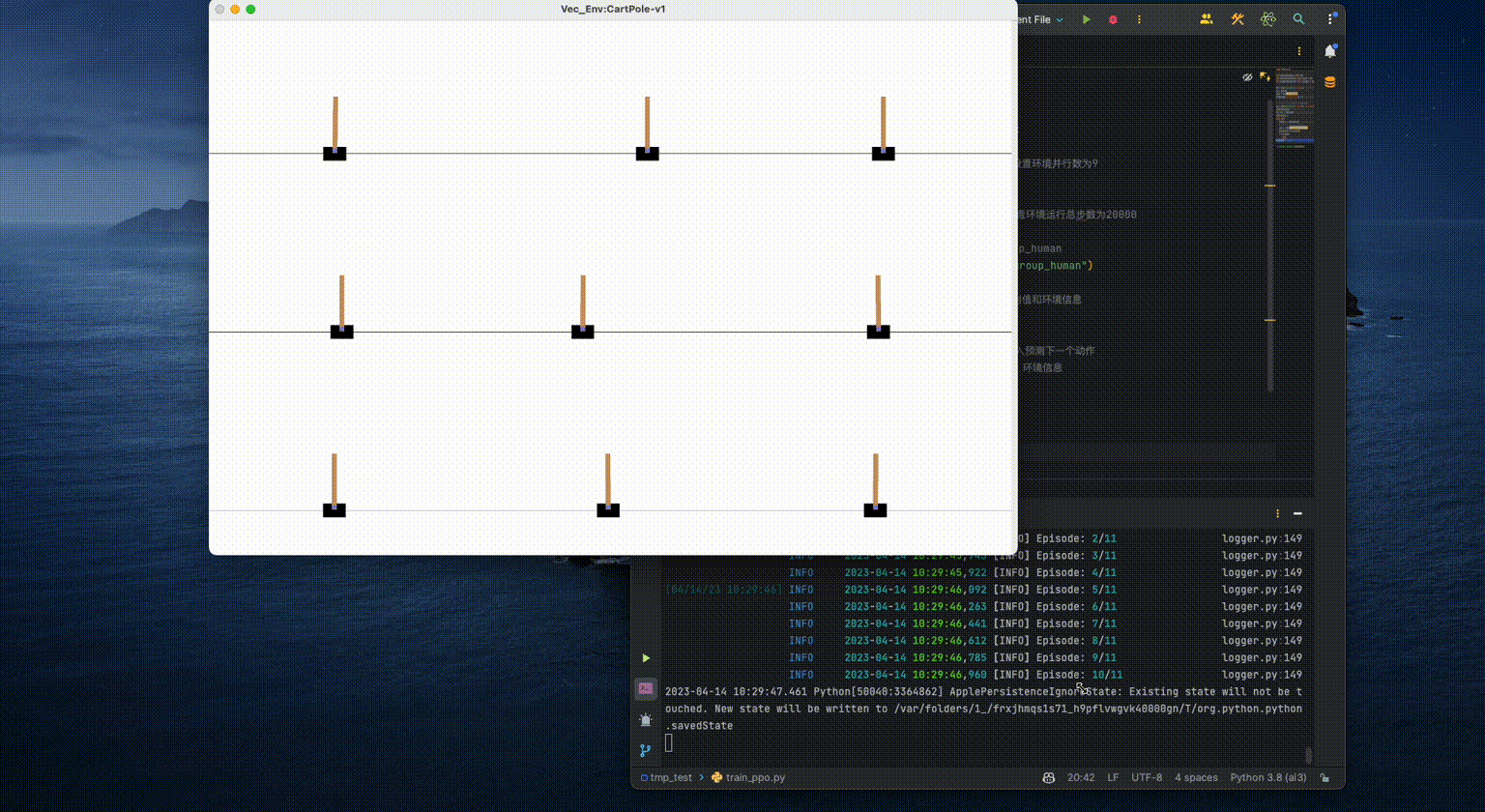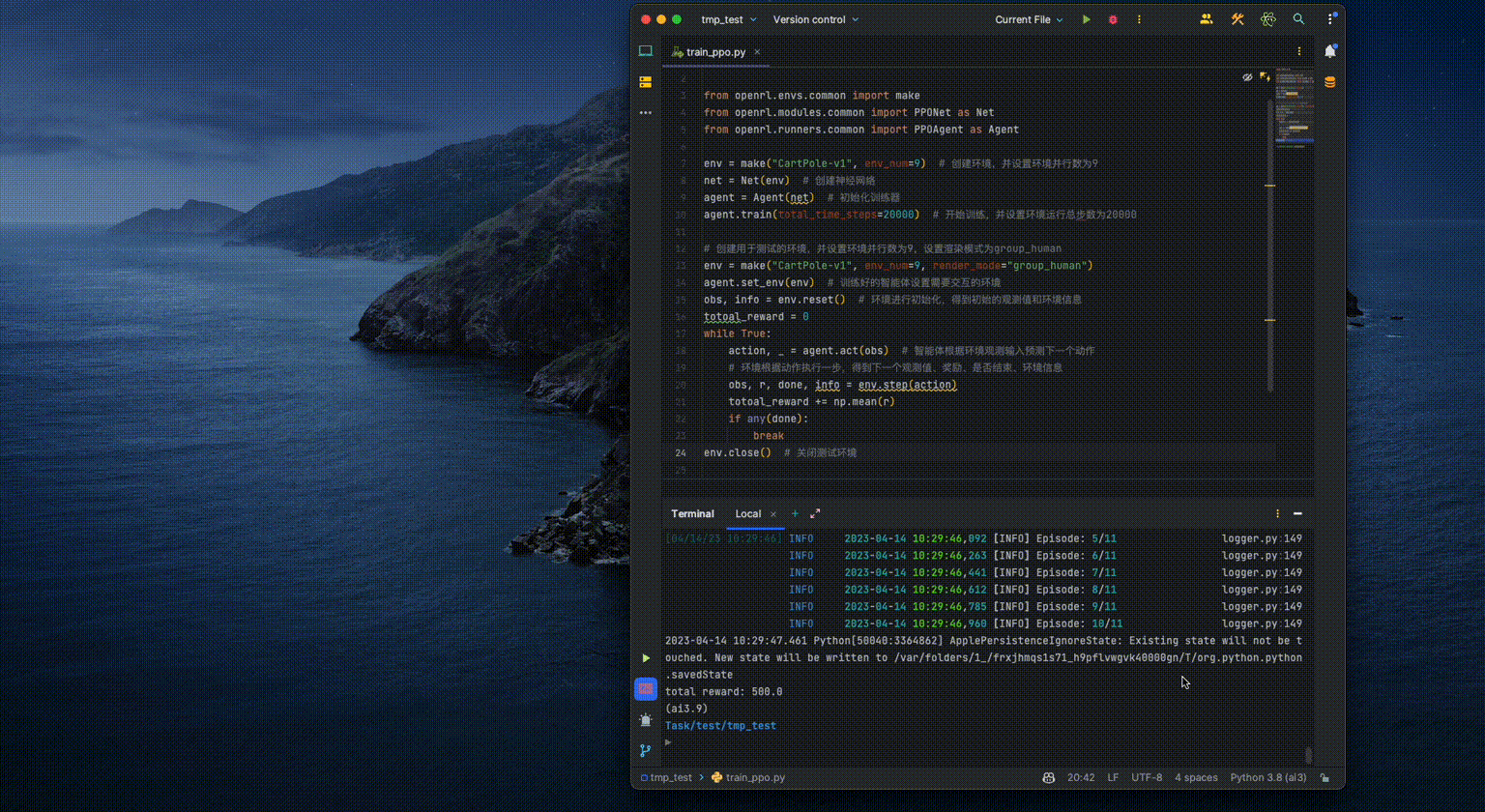
Note
If you run test code on a server machine you can not use a visualization interface. You can set the render_mode as “group_rgb_array”,
then call env.render() after each step to get the environment image.
In the following sections, we will use a more complex multi-agent reinforcement learning task (MPE) as an example, to introduce how to set training hyperparameters, how to switch between parallelism mode and serial mode, and how to use wandb.